I’m writing this message up in the air over the desertic landscapes of Nevada as I’m flying back to California from ng-conf 2023. It has been two days filled with lots of information, and I will unpack some of the major announcements in more detail in the following newsletters.
For now, I’ll focus on some rapid-fire news grouped by topic:
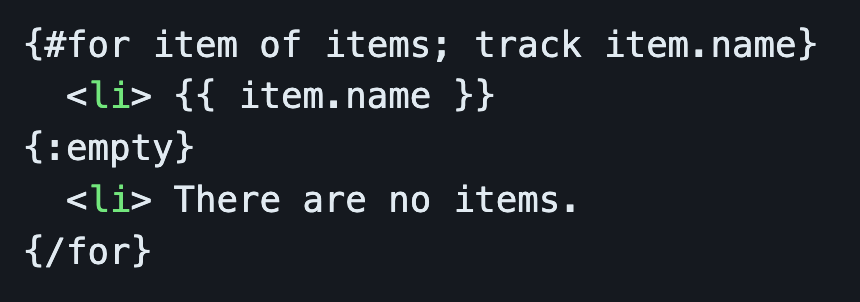
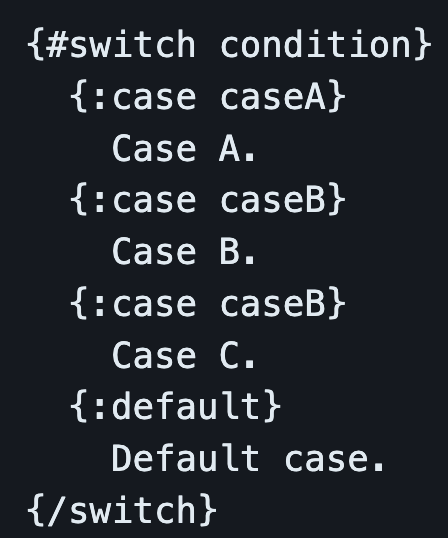
RxJs
- RxJs 8 is coming out soon, and it will be 30% smaller than RxJs 7 and 60% smaller than RxJs 6!
- Will have support for
async / awaitsyntax for Observables. - We will have some new syntactic sugar for chaining operators using a
rx()function. Code such asobs$.pipe(map(...), filter(...))will be writable asrx(obs$, map(...), filter(...)). Optional, yet good to know.
NgRx
- Support for a Signal Store is coming soon
Endbridge
- The ambitious project that aims to convert Protractor tests to Cypress tests automatically is 90% feature complete, just in time for the end-of-life of Protractor this summer.
Other cool news
- Bard, Google’s response to ChatGPT, is built with Angular!
- Analog.js is a meta-framework for Angular apps. It supports server-side rendering, static pages, back-end APIs, and regular Angular front-end code all in one project, all in Javascript. Similar to Next.js for React. Analog is still a work in progress but looks promising.