This is the second guest post by Duncan Faulkner. You can read his first post on Angular Material here. This is the second post in this series.
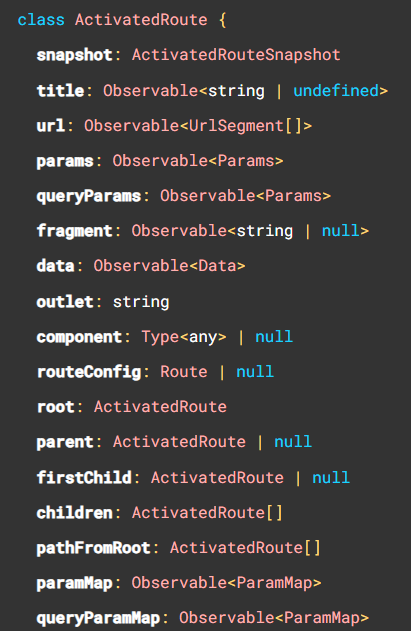
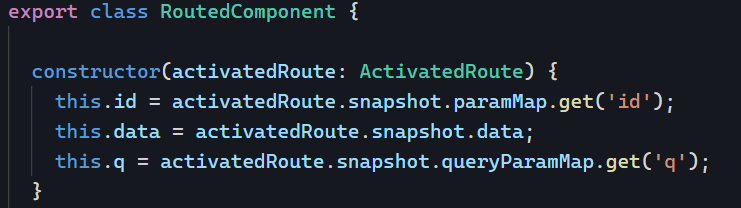
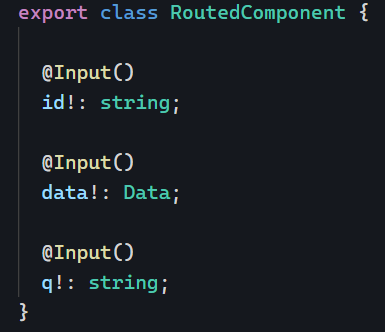
The mat-slider was recently rewritten in Angular 15 as part of a refactoring towards MDC (Material Design Components for the Web). The most notable change to the mat-slider is the element now requires up to two input elements, instead of just a mat-slider element, this allows us to use the slider as either a single slider (with one input) or a range (with two inputs).
The original mat-slider looked like this in versions prior to Angular Material 15:
<mat-slider></mat-slider>Code language: HTML, XML (xml)
And in versions after 15:
<mat-slider>
<input matSliderThumb />
</mat-slider>
<mat-slider>
<input matSliderStartThumb />
<input matSliderEndThumb />
</mat-slider>Code language: HTML, XML (xml)
Slider usage options
It’s also possible to set the range slider to have a min/max or both, for example:
<mat-slider [min]="30" [max]="75">
<input matSliderStartThumb />
<input matSliderEndThumb />
</mat-slider>Code language: HTML, XML (xml)
If min is not supplied then zero is assumed, likewise if max is not supplied then one hundred is assumed. If step is supplied then maxis required otherwise the slider will not be able to calculate the step division.
The thumbLabel directive has now been replaced with a new discrete attribute, this controls whether the value indicator tool-tip is shown when the slider is dragged.
<mat-slider thumbLabel></mat-slider>
<mat-slider discrete>
<input matSliderThumb />
</mat-slider>Code language: HTML, XML (xml)
To show the tick-marks on the slider add the showTickMarks attribute.
<mat-slider showTickMarks>
<input matSliderThumb />
</mat-slider>Code language: HTML, XML (xml)
For now the tickInterval property has been removed from the API, though this is being reviewed and could be reintroduced in the future. If we want to define the interval of the tick marks we use the step property and the tick marks will match the step:
<mat-slider discrete showTickMarks step="10">
<input matSliderThumb />
</mat-slider>Code language: HTML, XML (xml)
The displayValue property has also been removed in favour of the new displayWith this property controls the text value of the indicator, we need to provide a function for this property where we can manipulate the value to be displayed. We use the min property to set the lowest value, the max property to the highest value we want the slider to be an set the step property to what we want the increment to be.
<mat-slider min="0" max="100000" step="1000" [displayWith]="updateLabelWithFn">
<input matSliderThumb />
</mat-slider>Code language: HTML, XML (xml)
export class MySliderComponent {
updateLabelWithFn(value: number): string {
return value >= 1000 ? Math.round(value / 1000) + 'k' : `${value}`;
}
}Code language: JavaScript (javascript)
The updateLabelWithFn function takes the value from the slider and [in this instance] if the value is greater than or equal to 1000 then it will round the number and divide it by 1000 and concatenate the letter k to the end, this helps to keep the text small and in the thumbLabel.
The valueText property has also been removed, we now have two options we can use the input’s aria-label-valueText or use the displayWith property.
<mat-slider [valueText]="someTextValue"></mat-slider>
<mat-slider>
<input [attr.aria-valueText]="someTextValue" matSliderThumb />
</mat-slider>
<mat-slider [displayWith]="displaySomeTextWithFn">
<input matSliderThumb />
</mat-slider>Code language: HTML, XML (xml)
With the rewrite the API of the slider has also changed and has introduced two new components the MatSliderThumb and MatSliderRangeThumb and provide the following properties:
@Input() value: number@Output() valueChange: EventEmitter@Output() dragEnd: EventEmitter@Output() dragStart: EventEmitter@Input() percentage: number
And the following methods:
There are two notable absences from the mat-slider and these are:
- invert – this reversed the start and end of the slider
- vertical – this rotated the slider 90°, you could also invert a vertical slider
These have been removed as they are not part of the Material Design Specification for the Web (MDC).
Changing the color of a slider
Like all Angular Material components we can change the color of a mat-slider using the color property.
<mat-slider [color]="primary">
<input matThumbSlider>
</mat-slider>Code language: HTML, XML (xml)
In our next post, we’ll see how to migrate from Angular Material 14 to 15+.