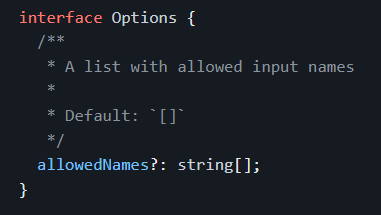
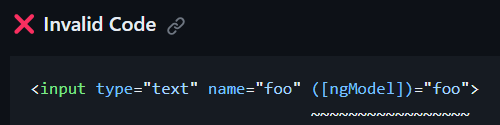
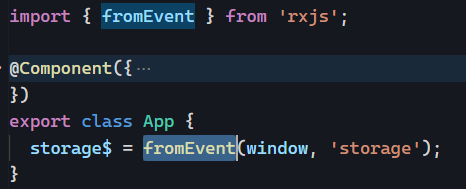
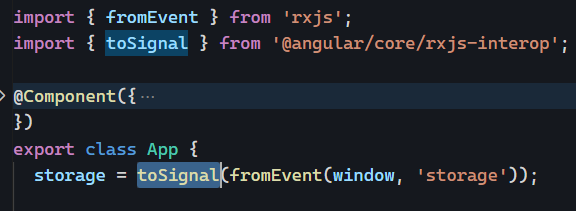
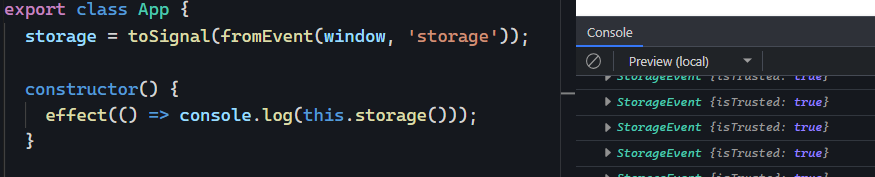
Last month, I discussed eslint and how to use that tool to parse your code and receive feedback on best practices and possible improvements.
Today, I want to mention an eslint plugin explicitly written for RxJs with Angular: eslint-plugin-rxjs-angular.
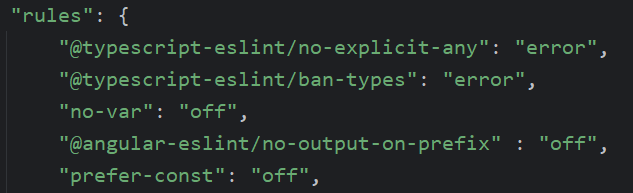
This plugin adds three possible validation rules:
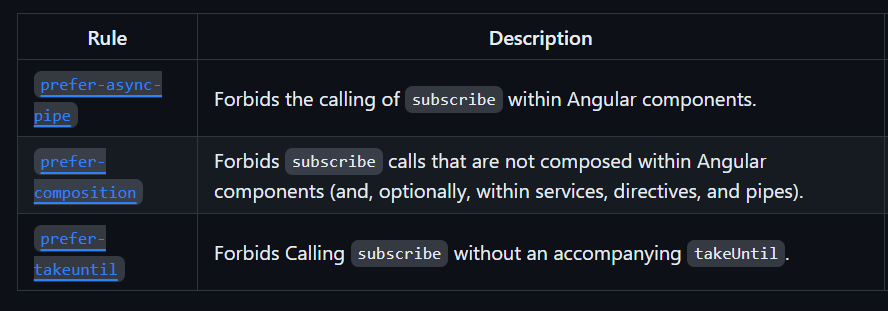
All rules are optional, and it doesn’t make sense to use all of them at once because these best practices are contradictory in the sense that the goal is for you to choose one of these three approaches and be 100% consistent with it:
- The first rule will enforce that you always use the
asyncpipe in your components. - The second rule doesn’t care about the
asyncpipe but wants to ensure you unsubscribe on destroy. - The third rule is the most specific, as it enforces that you always use a Subject with
takeUntilto unsubscribe in your components.
I’d suggest using the first rule only because we covered before that the async pipe is the safest and most performant option. And remember that you can always use the async pipe. There are no excuses!