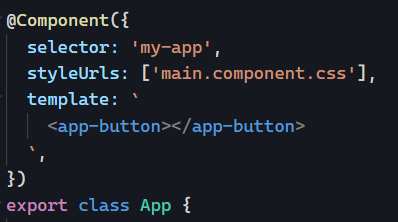
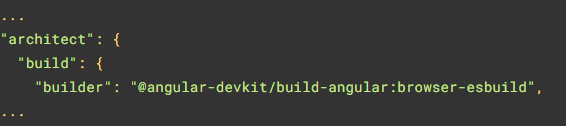
Have you ever wondered how to highlight a specific HTML element, such as a link or a button, when a particular URL is selected? Something similar to this:
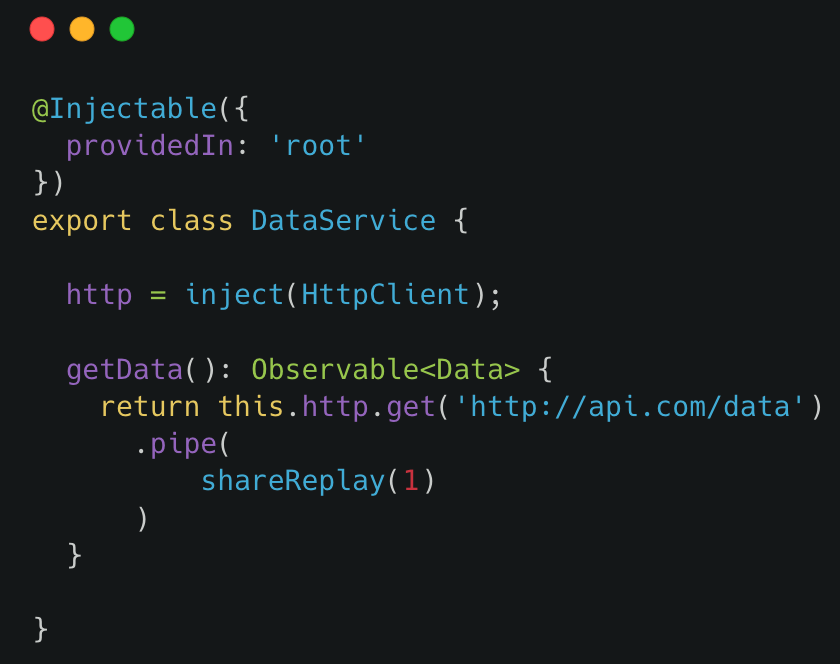
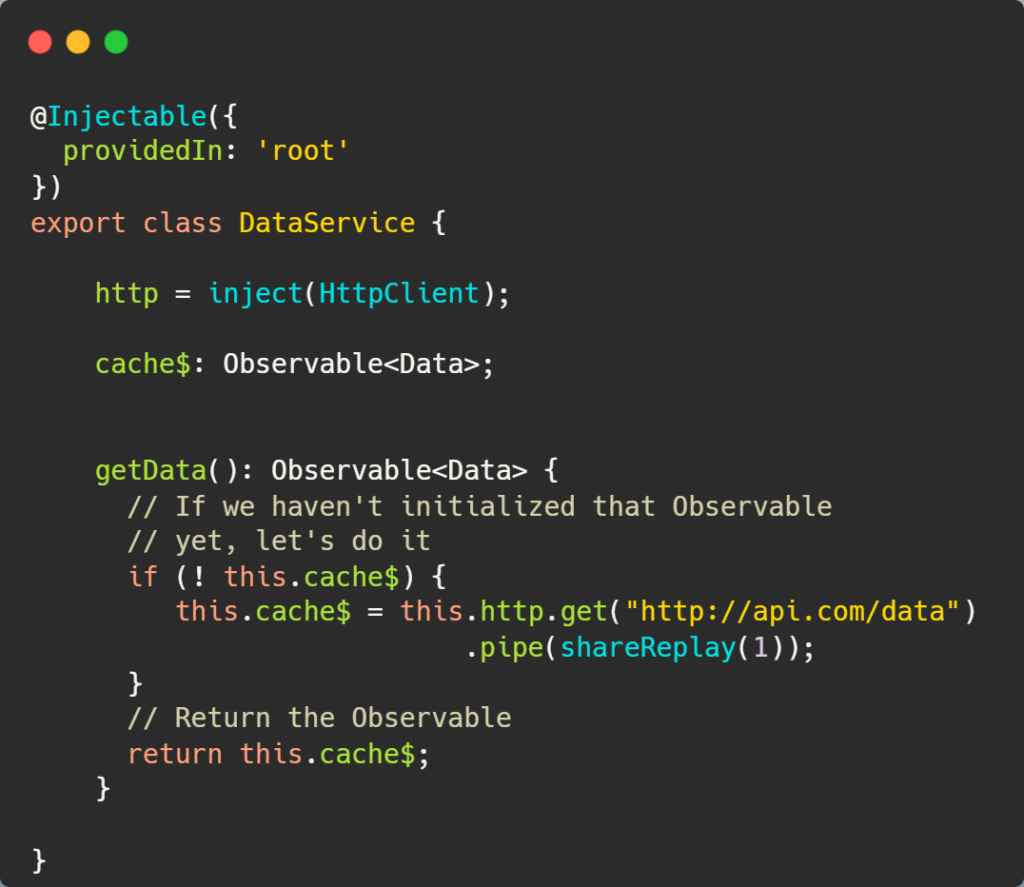
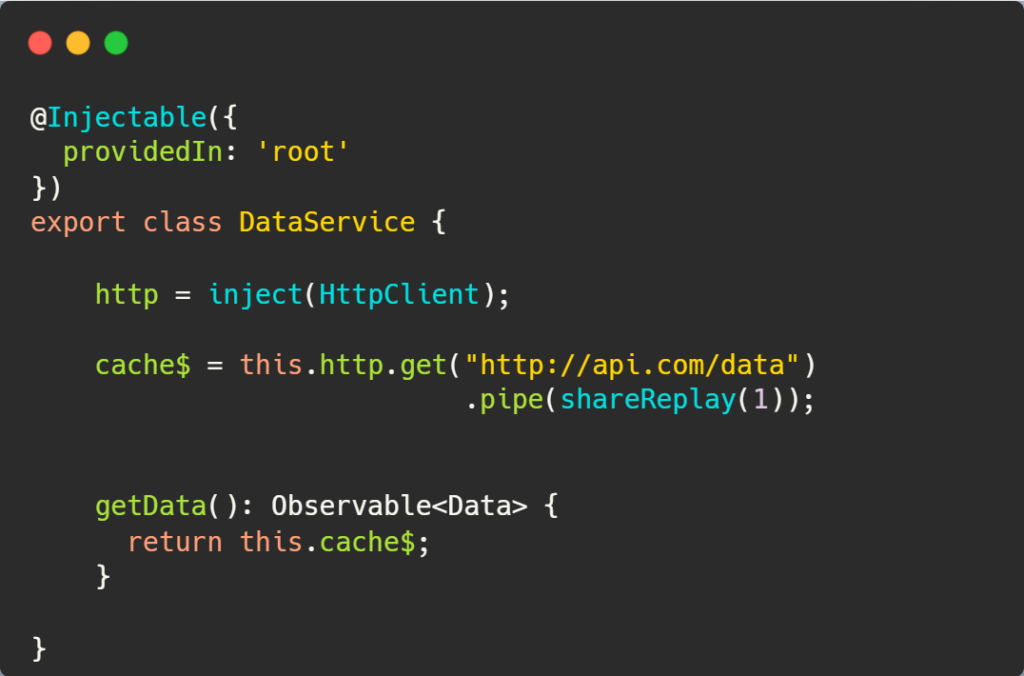
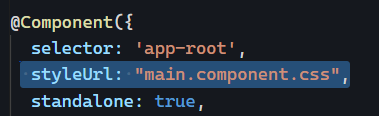
The good news is that there is a specific directive for this called routerLinkActive. Here is how you can use it:

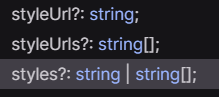
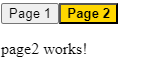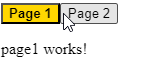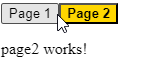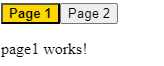
The value set to routerLinkActive is the name of a CSS class (or several CSS classes) that gets applied to the HTML element when the current URL path matches the path of the routerLink directive on that same element. In other words, if the path is page1, then the button element has an active class applied to it.
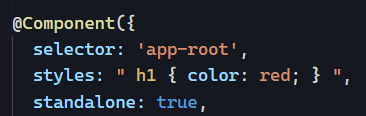
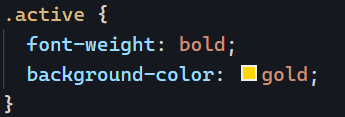
As a result, all I did to style the above example was add that CSS class definition to my global CSS file:
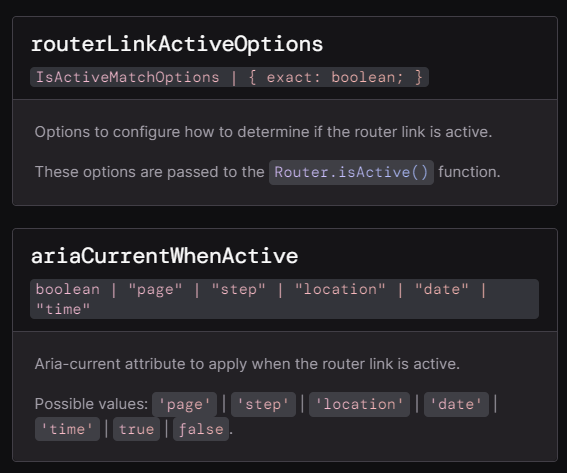
And that’s it! Note that the directive supports several other options documented here:
You can see my example in action on Stackblitz here.