This week, we get back to the 3-2-1 format of the newsletter. I’m posting a few essential articles to revisit, updates to know about, and one question to ponder – all ideas of good practices to adopt in 2025:
Three short articles to revisit:
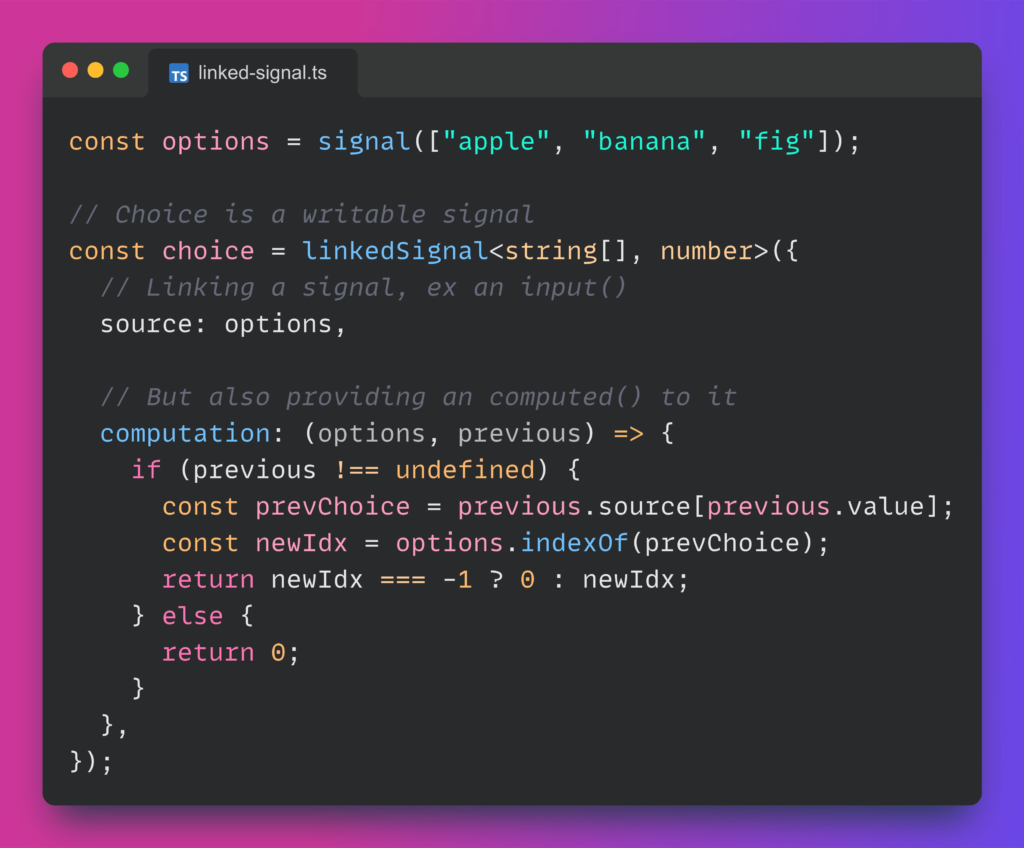
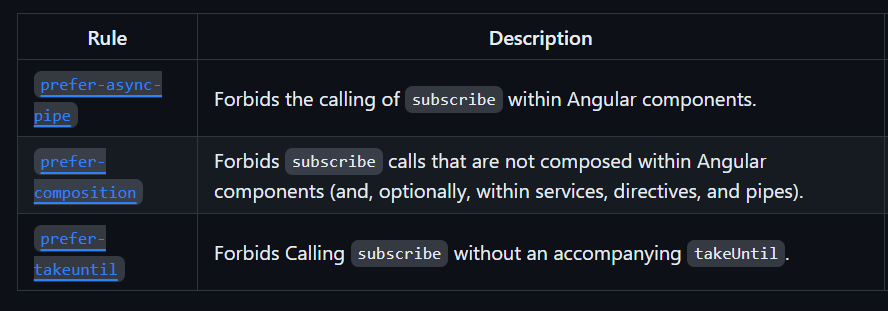
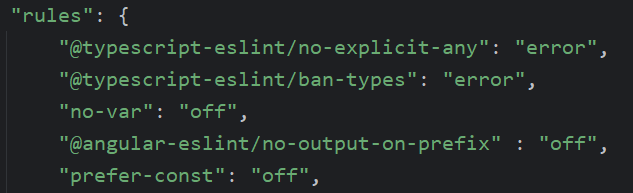
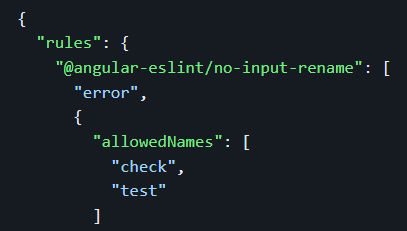
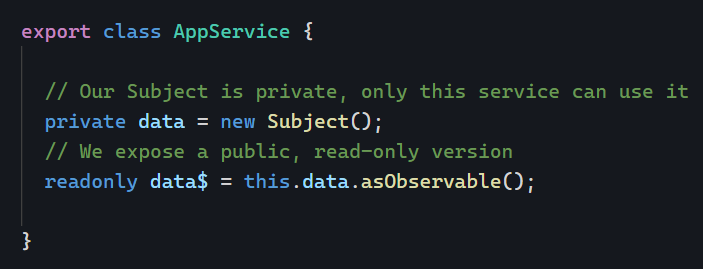
eslintis a nice and easy way to ensure you (and your team) are following best practices and not using shortcuts or making any mistakes in your code. Learn the basics of eslint here, how to fine-tune your eslint config so it fits your needs (you can disable rules you don’t like), and also how to use extra rules for RxJs to favor the use of theasyncpipe, for instance.
Two Angular updates:
- Ng-conf has released more videos from the 2024 event for free on YouTube. This is another good way to improve your Angular skills during the Holiday season! We’re still waiting for a date for the 2025 event.
- The Angular team started creating a playlist of short videos (30 secs each) about Angular 19—a nice and fast way to learn about some of the new features of Angular 19.
One question to think about:
What’s your current Angular version? The end-of-year slowdown could be an excellent opportunity to find some time to upgrade to v19. Use my upgrade guide here for more info.