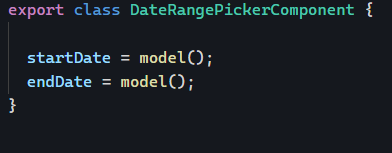
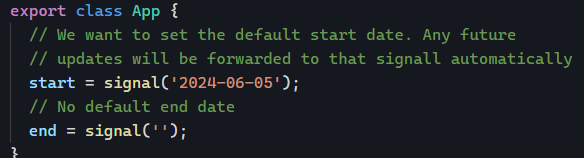
Angular apps created with the Angular CLI used to have automatic environment creation built-in for new projects. While this automation was removed in recent years to simplify the learning curve of Angular, it is still possible to add support for different environments using the command:
ng generate environments
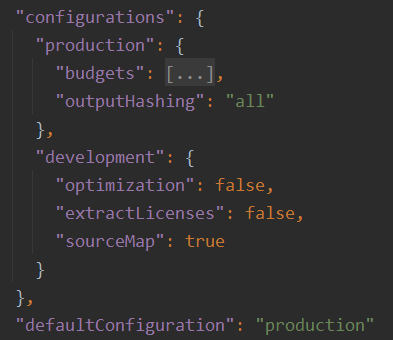
Before we generate such environments, it’s important to take a look at angular.json in the root folder of any Angular project, more specifically, the section called configurations in the build section:
This tells us that our project has two different configurations: production and development, and the default config for the ng build command is production.
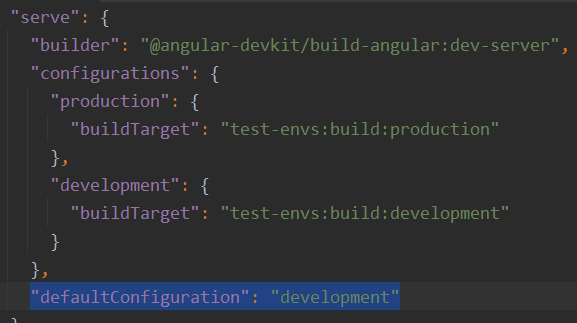
Note that the serve section of angular.json has a similar config that extends the build targets and overrides the default configuration by making it development, which, as a result, is what we use when we run ng serve:
If we want to override the default configurations when running ng serve or ng build, we can do this by adding a configuration flag to the command and making it point to the proper configuration name, for instance:
ng serve --configuration=production
ng build --configuration=development
How do we plug environment variables into this?
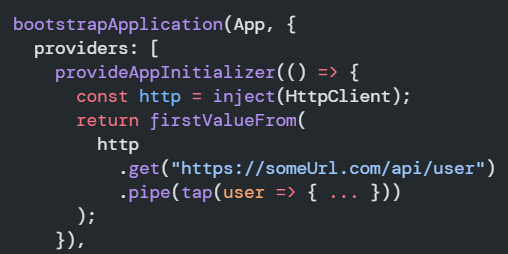
When we run ng generate environments, the Angular CLI does two things:
It creates two new files in src/environments: environments.ts (the environment for production, which is also the default) and environment.development.ts for development.
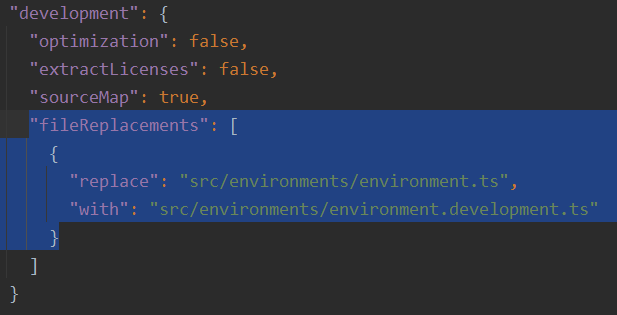
angular.json gets updated with the following highlighted syntax:
As you can see, this instructs the builder to replace the production environment file with the development file when we use the --configuration=development flag.
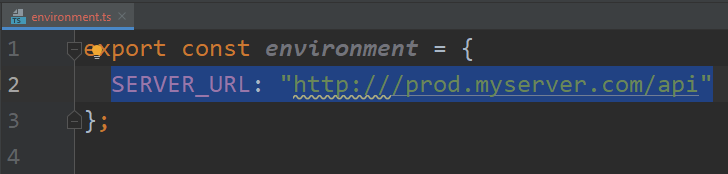
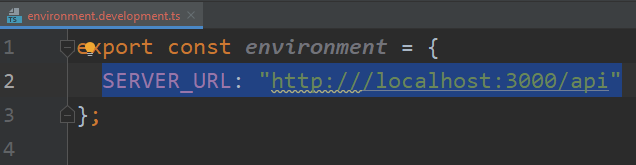
Such environment files can contain any environment variables we want. For instance, say I want to define a SERVER_URL that is different for production and development. I can do that:
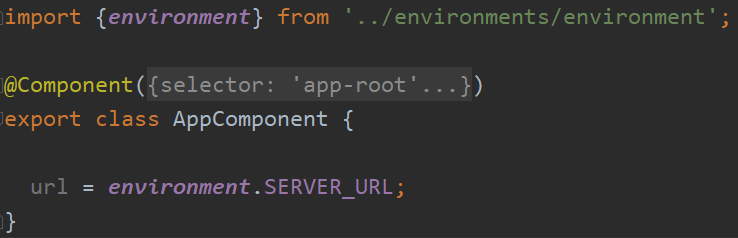
Now, to use such environment variable in my code, all I need to do is import it as follows:
Important: The import has to be from /environments/environment. Angular will pick the correct configuration based on the flag given to the build or serve command.
How do you create environments for QA, pre-prod, and more?
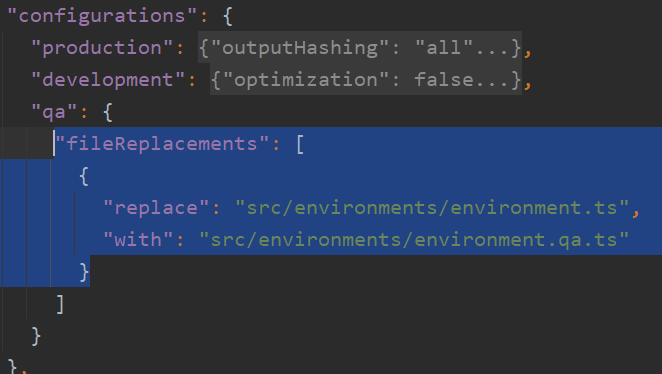
Now that we know that angular.json is the file where all this magic happens, if we want to create a qa environment, we can head to the configurations section of build, add a new configuration block with the name q (or anything you want, of course), and make the file replacement to a new file that I call environment.qa.ts:
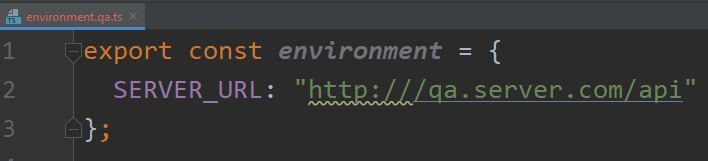
Then, I can create that environment file under src/environments and add any variables I need in it:
And that’s it! We covered how to create environment variables for production and development and how to create other custom environments we might need.