Yesterday, we covered what markForCheck() can do in terms of change detection and why it could be needed at times.
Regarding best practices, I often mention using the async pipe or Signals to improve change detection and performance in our apps. Why is that? That’s because both the async pipe and Signals have some extra code to help Angular detect changes.
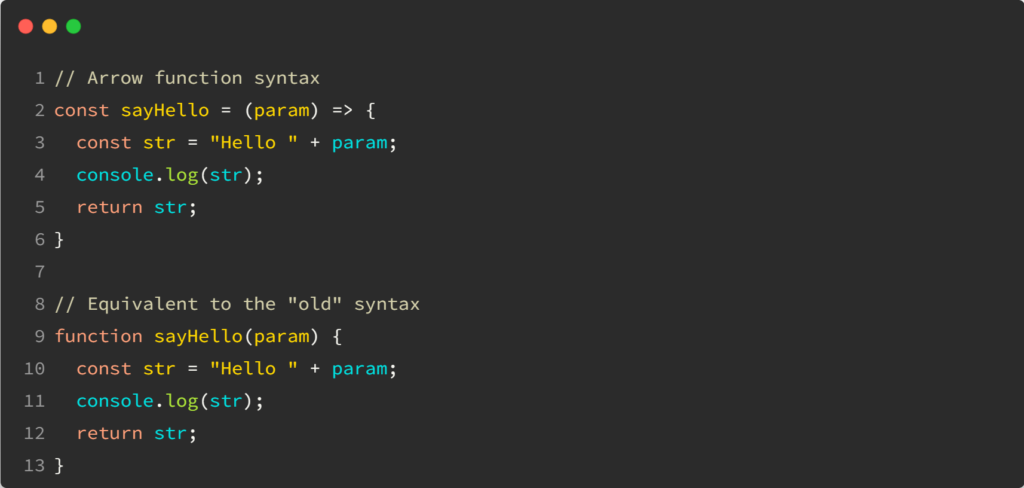
Here’s what we can find in the source code of the async pipe:
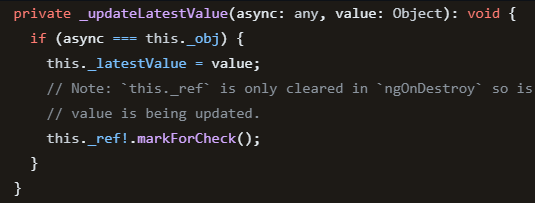
The last line of code indicates that whenever an async pipe receives a new value, it marks the corresponding view for check, triggering the need for change detection. That’s the reason why the async pipe works well even when used in an OnPush component: Its internals override the behavior of whatever change detection strategy we use.
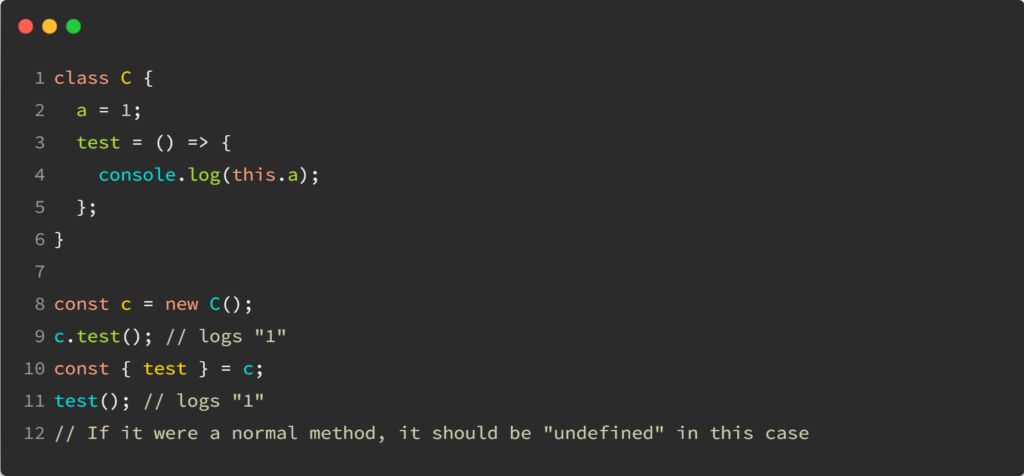
Signals do something similar by marking their consumers (or “subscribers,” in a sense) as dirty when the Signal value changes:
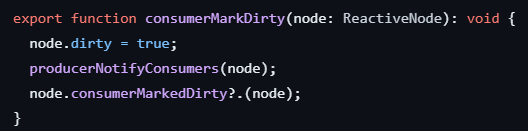
As a result, and back to the point I was making yesterday, Instead of trying to use markForCheck() directly in our code, we should rely on the tools designed to do it automatically and in an optimized fashion for us.
Conclusion: Always use the async pipe with RxJs (you can always do so) or use Signals for an even better experience.