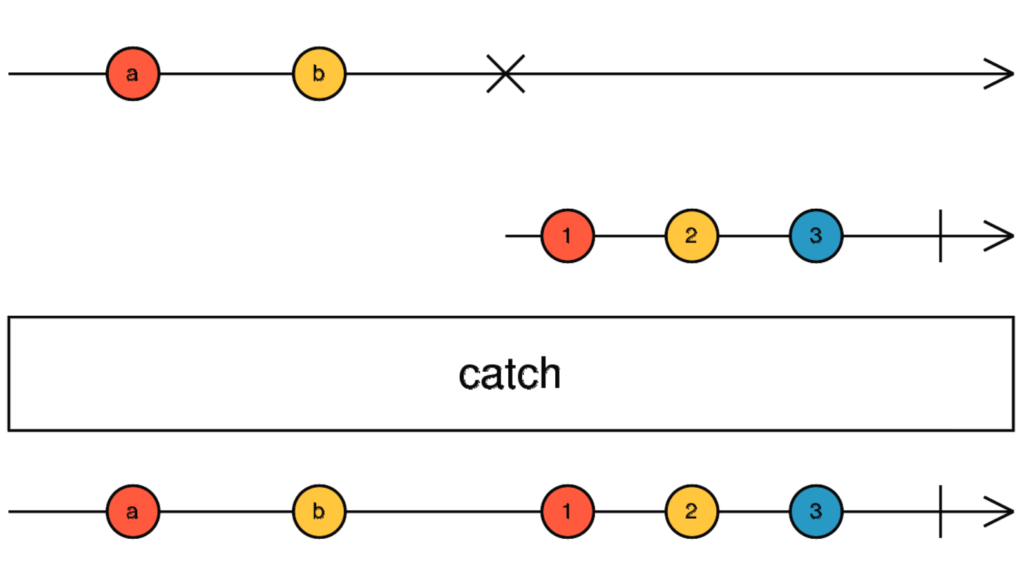
After talking about how to create Signals, how to update them, and how to derive a Signal value from other Signals, let’s look at how we can register side effects out of any number of Signals.
Enter effect(). The behavior of effect() is almost the same as computed(), with one major difference: computed() returns a new Signal, whereas effect() doesn’t return anything.
As a result, effect() is suitable for debugging, logging information, or running some code that doesn’t need to update another Signal:

You can see that code in action here on Stackblitz.
Note that trying to update a Signal within an effect() is not allowed by default, as it could trigger unwanted behavior (infinite loop such as SignalA triggers update of SignalB that updates SignalC that updates SignalA – and around we go).
That said, if you know what you’re doing and are 100% sure that you won’t trigger an infinite loop, you can override that setting with the optional parameter allowSignalWrites as follows: